
How difficult for black are Fischer Random starting positions?
What humans and Stockfish think about it.In 1996 Fischer proposed to change the classical starting position of chess to a random new one with a very precise rules.
Bishops must run in different color squares, king be placed between rooks to enable castle identical to classic one and queen and knights ad libitum, resulting 960 possible starting positions.
Without pretending it, these rules provoke that some starting positions are more difficult than others for black to get a balanced game. After my experience and according other studies, the most difficult position for black is #80, where if white makes the strongest moves, not easy to guess for humans, black must go through a narrow path to do not lose.
A recent study made by physicist Dr. Barthelemy takes a different point of view. He arrives to the conclusion that the position #226 is the most complex to play, which is not exactly the most initially challenging but the most difficult one to take decisions during its evolution. He made a mathematical study about complexity of a chess position based in Information Theory and Statistical Mechanics tools adapting original parameters of energy and temperature to chess evaluations in centipawns by module and human capacity to discriminate the evaluation between two moves respectively. Resulting in the highest complexity fell on #226. Looking like familiar is an additional difficulty. Personally I find fascinating how he makes a scientific study, which means objectivity, on difficulty, which is subjective.
Now, I want to let players speak through their games. Practice results of FRC will give us how much difficult are starting positions for humans, not just the module evaluation that cannot consider human way of thinking. I will make a 'democratic' evaluation of positions. What I did was:
a) Data collection:
I) Download all monthly pgn databases from Lichess since its creation until december 2025, 149 files, 38 GB. Lichess makes it easy because a list of links can be obtained in a txt file and put it in a download manager. url text file.
II) Purge bullet games (time<3m), as it brings too much chaos that I decided to remove. A Python script was necessary to remove from each month all bullet games and create a new clean pgn. There were originally 26 million games, bullet were around 30-40%, depending on file as I saw in the script reports. After a patiente calculation near 17 million games were left.
III) A second script extracts to each position from the new no-bullet databases the next data:
W = number of white wins
D = number of draws
B= number of black wins
N = number of games
white and black elo averages
white score SW = (W + 0,5·D)/N
All these data were written in a csv file to be open with Calc or Excel. Just arranging SW column I already have a first human evaluation which can be considered as a relative evaluation of difficulty, it is not absolute as Stockfish is. But this action fails, SW by itself would be correct only if elos were the same for white and for black. I will explain how I fixed it in data treatment part b) I).
IV) Run a third script to make Stockfish 18 evaluate all 960 starting positions. The configuration used was not far from what can be used in Lichess,
DEPTH = 24
TIME_LIMIT = None
engine.configure({
"Threads": 4,
"Hash": 1024,
})
Results were written in another csv file with evaluation in centipawns.
V) In a second filter of games I just considered results of games where both players had a ranking > 1800. A fourth python script, very similar to the first one, wrote the new pgn files with such condition. I got a set of 3,657,123 games and repeated step III).
b) Data treatment:
I) Human data
Trying to include elo bias in white score, I calculated with elo formula, https://en.wikipedia.org/wiki/Elo_rating_system, expected result for white EW of each position using the average elos, It gives me a gap between real score of white SW ,and expected score EW, G = SW - EW and I sorted this column to get what positions were better for white. G gives the part of white results that are due to position and not to relative strength of players.
Those positions were (Table with first tenth and database features)
| elo filtering | number of games | elo average | Top ten best starting positions for white after gap arrangement |
| No | 16,328,936 | 1700 | 384, 0, 608, 512, 676, 192, 704, 477, 864, 576 |
| >=1800 | 3,657,123 | 1970 | 672, 478, 783, 488, 959, 463, 372, 192, 67, 432 |
| >=2100 | 210,554 | 2225 | 0, 13, 37, 3, 10, 53, 1, 96, 8, 31 ** |
| >=2200 * | 22,426 | 2325 | 851, 216, 469, 862, 125, 339, 247, 390, 376, 175 |
* This database does not include #518 classical position, and only games between 2021-25
** Position #0 had a SW = 0,71 !!
Which one is more reliable? I have no idea, it would be the one with highest elo but there are very few games. Personally, the second one could be considered as the best, it has enough games and not too much low elo, just in case I will compare SF data with all of them.
I have a home-made database where the sources are the tournaments I found, like Grand Slam, Grenke Open, etc. The problem is not that it has only 6931 games, the issue is that positions are not uniformly represented like in other databases, a position played in Grenke Open has much more games than other ones, there were even 10 positions without any game and many others with only 1 or 2.
II) Engine data
Stockfish 18 average evaluations is 32.18 cp, median = 31, mode = 33 and standard deviation = 11.88. Classical 518 position is evaluated with 36 cp.
I said previously that is already known that position #80 is the most difficult for black. What have SF 18 said?
#80 is in second place with an evaluation of 83 cp. Which is the first one then? #879, its twin with 89 cp. Notice that 879 + 80 = 959 . It happens in all positions and their twins. You may see that position in blog's image.
The top ten positions from most to less difficulty for black are:
879, 80, 399, 935, 279, 760, 752, 557, 620, 794 with respective evaluations:
89, 83, 80, 74, 72, 72, 69, 68, 67, 67.
There is another position with evaluation of 67 cp, #868, afterwards evaluation drops very slowly until 3 cp. The Cinderella position is for #257, I ignore why. Position #226 is ranked in 930 place, because what is measured here is completely different from Dr. Barthelemy's study. He gives a value for complexity for both players during game evolution, rather I just compare what SF thinks about each starting position with human performance. He measures dynamics, while SF measures statics.
III) Human vs. SF
Are Human and SF results related? Are SF data a good prediction for Human results?
Seeing only the top ten positions we cannot get a global vision. So I made the following procedure.
a) For every database:
Pearson's correlation coefficient between expected results EW and real results SW. Coefficient was very weak, as it can be seen in the table below, which means that position determines the game result more than elo.
Assuming that gap between real and expected results G = SW - EW is a good measure for human evaluation of positions:
Pearson's correlation coefficient between Gap and SF previsions. Also, coefficients were very weak.
| database | correlation between SW and EW | correlation between gap and SF evaluation |
| without elo filter | 0.148 | 0.148 |
| elo>=1800 | 0.204 | 0.08 * |
| elo>=2100 | 0.2645 | -0.0195 |
| elo>=2200 | 0.2171 | 0.049 |
* 0.111 using depth 40 evaluations that kindly editor, Arno Nickel, provided me, with other filters there is no significant change.
This coefficient measures degree of dependence, relation between variables is not detected.
Trying to look for hidden dependencies or confirm weak relation I split the 960 positions in 10 groups of 96 positions each one. It gives two sets of 10 groups, one for SF evaluation, the other for the gap of one database. Group #1 means the group less favorable for white and #10 the group with the best positions for white.
I made this crossed table 10x10 for the database of elo >= 2200
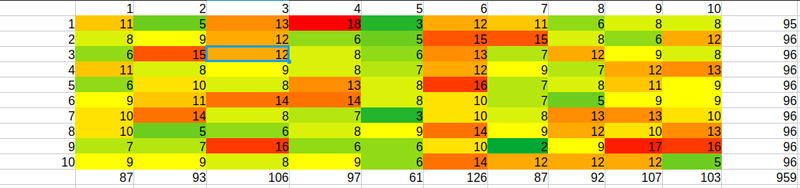
It is nicely colored because apart of a table is a heatmap.
How to read it? Rows are for human groups, and columns are for SF groups. In the right column and bottom row, there are partial sums. Total sum = 959 in right bottom corner cell, because database with elo>=2200 does not consider classical position #518.
A cell like (3,4) = 8 means that there are 8 positions in common between 3rd human group and 4th SF group. Thus, the most interesting group is (10,10). What positions are considered by both, humans and SF, as hard for black? Given that each group has around 96 positions, (10,10) = 5 means that they do not agree in almost anything. But, for curiosity, which those 5 positions are?
| position | SF evaluation(cp) | SF ranking |
| 18 | 52 | 49 |
| 336 | 50 | 71 |
| 760 | 72 | 6 |
| 794 | 67 | 10 |
| 839 | 49 | 86 |
Is this relevant or a near random result? Given that 5 is a low number of coincidences, I bet for random.
Finishing the analysis, I made a (greek letter ji) X^2 test. After tedious calculations, X^2 = 85.15 it means that dependence between previsions and practical results is very weak, confirming the conclusions of correlations already calculated.
A last observation
With an elo >= 1800 the same crossed table gives a (10,10) = 17 and X^2 = 92.45 with depth=24 and X^2 = 97.73 , meaning that there is a little relation between human results and SF evaluations. Without forgetting a low Pearson 0.080 and 0.11 respectively.
c) Conclusions
Relations between SF previsions and human results are very weak. No matter elo filtering. Why does this happen?
SF evaluation is objective and human play is subjective. A human game is subject to many random conditions: time troubles, mouse slips, lost of connection, wrong perception, fatigue, alcohol and drugs consum or any other psychological factor that affects the statistic data.
Human thoughts are based in patterns and SF is a brutal calculation force. As we do not know theory, our first moves are based in basic principles about development, space, center, pawn structure, etc, tactics apart. It is subjected to an easy mistake.
Take for example position #80, one of the hardest for black after SF. If white does not move 1.g4 the most adventage falls off and the tiger becomes a kitty. It is possible that, with time, players learn, if not opening theory, at least identifying the most critical positions and remember the best first moves.
In classical chess, module is used to improve new opening variations, players can learn from engine. In FRC is not possible. In my personal case, main SF utility is to frustrate me when I think that I made a good game,
d) Problems with all that stuff
- The most games are blitz. We all know what does it mean.
- Time troubles and subsequent mistakes can be a consequence of a difficult position, but I think this is extendible to all 959 positions, classical apart. Each position is a jigsaw puzzle.
- 960 elo is bad calculated, Lichess does not discriminate 1+0 of a 10+2 game, it makes that elo filters are not reliable. In the same way that in classical chess there is an elo ranking depending on game timing, it should be necessary in FRC.
- Long time games in 960 modality are not enough yet to make statistical calculations. Not only from strongest players. I hope in few years it will be remedied.
Play 960 is like to listen to atonal music when we only have listened to tonal music before, or try to look at an abstract picture after only have seen figurative paintings before.
You may also like
 IM theScot
IM theScotFrench Defense: The "Dullest" of All Openings
A foray into the evolution of the French Defence IM justiniano565
IM justiniano565Non human 960 openings IV
Flanks attacks I IM justiniano565
IM justiniano565Non human 960 openings II
What humans don't usually think about: finding new treasures RuyLopez1000
RuyLopez1000AI Slop is Invading the Chess World
Claiming that AI can teach chess is the latest fad CM HGabor
CM HGaborHow titled players lie to you
This post is a word of warning for the average club player. As the chess world is becoming increasin… thibault
thibault