@Willem_D said:
How does this evaluate this specific position: 4k3/8/8/4P3/3K4/8/7R/6r1 b - - 0 1
It's an almost Philidor position. For black (the defending side), there are 17 moves that draw with all equal evaluation. Bus as a human, I would definitely play Rg6, going into the standard Philidor position which is an easy draw.
I think the best move is the highest rated move (according to Stockfish) that you understand.

As you see, it doesn't apply to every position. With a PV of 5, the 17 moves are not visible. The moves that are there have been found from depth 1 and 2. Even with 10 PVs, this system doesn't reveal much more, as you basically get a random sample of the 17 drawing moves in no particular order:
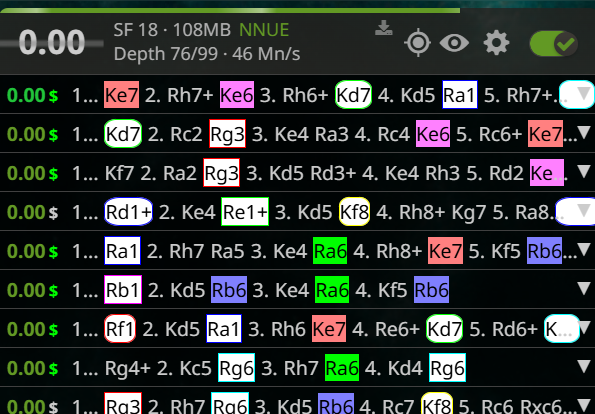
But in a position that has a few reasonable moves, a number less than the PVs, some insight could be extracted. Also note that engines don't always follow a deterministic path. Even if you get to the same moves and evaluations, a move could have been considered for the first time at any depth.
@Willem_D said:
> How does this evaluate this specific position: 4k3/8/8/4P3/3K4/8/7R/6r1 b - - 0 1
>
> It's an almost Philidor position. For black (the defending side), there are 17 moves that draw with all equal evaluation. Bus as a human, I would definitely play Rg6, going into the standard Philidor position which is an easy draw.
>
> I think the best move is the highest rated move (according to Stockfish) that you understand.

As you see, it doesn't apply to every position. With a PV of 5, the 17 moves are not visible. The moves that are there have been found from depth 1 and 2. Even with 10 PVs, this system doesn't reveal much more, as you basically get a random sample of the 17 drawing moves in no particular order:

But in a position that has a few reasonable moves, a number less than the PVs, some insight could be extracted. Also note that engines don't always follow a deterministic path. Even if you get to the same moves and evaluations, a move could have been considered for the first time at any depth.
One thing that I think would be very useful is, for each move, to know how likely is it that a human plays that move?
Suppose in a certain hypothetical position, the engine recommends two "top" moves. But the first move has a line that contains many moves that are hard to find (unlikely to be played by a human). But the 2nd move is a line that has all moves that are easy to find (likely to be played as a human). Then I will definitely prefer the 2nd move.
I'm just speculating, but I think you could train a neural network on many human played games (both high and low rated). This neural network can then suggest moves that are not necessarily the best move, but the move that is most likely for humans to play. I remember the AlphaGo documentary, where at some point they also mention that they know how likely a move is to be played by a human. (AlphaGo was also trained on human games, as opposed to the zero-knowledge engines we have now).
And such a network can also be used for lower-rated bots. To make the bot make "human" mistakes, instead of a random blunder that makes no sense.
One thing that I think would be very useful is, for each move, to know how likely is it that a human plays that move?
Suppose in a certain hypothetical position, the engine recommends two "top" moves. But the first move has a line that contains many moves that are hard to find (unlikely to be played by a human). But the 2nd move is a line that has all moves that are easy to find (likely to be played as a human). Then I will definitely prefer the 2nd move.
I'm just speculating, but I think you could train a neural network on many human played games (both high and low rated). This neural network can then suggest moves that are not necessarily the best move, but the move that is most likely for humans to play. I remember the AlphaGo documentary, where at some point they also mention that they know how likely a move is to be played by a human. (AlphaGo was also trained on human games, as opposed to the zero-knowledge engines we have now).
And such a network can also be used for lower-rated bots. To make the bot make "human" mistakes, instead of a random blunder that makes no sense.
@Willem_D said:
One thing that I think would be very useful is, for each move, to know how likely is it that a human plays that move?
:D That is exactly the issue I have been trying to avoid with this. A lot of work has been done trying to determine what people would do. But other than the complexity of simulating messy human thought there is also the problem that different people think differently, while algorithms are probabilistic. So even if you would harvest the brain of a person so that you could power a machine to determine what a human move would be, it would still be crap at predicting other humans.
Instead, this method is less insightful, but fast, consistent and reliable. Hopefully it shows something useful, but it might not. Only time will tell.
@Willem_D said:
> One thing that I think would be very useful is, for each move, to know how likely is it that a human plays that move?
:D That is exactly the issue I have been trying to avoid with this. A lot of work has been done trying to determine what people would do. But other than the complexity of simulating messy human thought there is also the problem that different people think differently, while algorithms are probabilistic. So even if you would harvest the brain of a person so that you could power a machine to determine what a human move would be, it would still be crap at predicting other humans.
Instead, this method is less insightful, but fast, consistent and reliable. Hopefully it shows something useful, but it might not. Only time will tell.
So if I understand correctly, a move has a low cost if it's found by the engine at low depth? And it has a high cost when the engine needs to seek really deep in order to see the move is good?
I think it's a pretty clever idea. I think it is especially suited to discard overly complicated engine lines.
So if I understand correctly, a move has a low cost if it's found by the engine at low depth? And it has a high cost when the engine needs to seek really deep in order to see the move is good?
I think it's a pretty clever idea. I think it is especially suited to discard overly complicated engine lines.
Really cool! Lichess tools is becoming a great success!
Really cool! Lichess tools is becoming a great success!
@TotalNoob69 said:
@RuyLopez1000 said:
If a candidate move is 1-2 pawns (100cp = 1p) from the optimal move eval, then wouldn't a massive amount of moves, be considered a candidate at depth 1? I mean it feels like at depth 1 surely a lot of moves would be classified within 1-2 pawns from the optimal move considering how large a margin that is? And if a large amount of moves has the same price, then that wouldn't give any info.
It was a general concept. For example I am just now coding something that considers the first time a move entered the engine PVs the depth at which it "figured it out". This changes significantly, though, if I configure 1pv, 10 pvs or 500. In other places in LiChess Tools I calculate the winning probability based on centipawns. Anything which is 1% closer to the best estimation is considered good, 10% less is a mistake and 20% is a blunder. The definition of the "candidate move" matters.
I don't know what's the best formula. That's why I was waiting for the likes of @hollowleaf and @jk_182 and @noobmasterplayer123 and @matstc to weigh in :)
I am just saying that even if computers find the moves differently than people, the time (nodes, depth, etc.) they spend to consider a move as possibly good can be considered a cost or price of the move. The higher the cost... err... I don't know. That's what I am trying to figure out.
I will conduct a more in-depth analysis and explore how to express it mathematically. I like the idea, though maybe it can be tweaked more, lets see.
@TotalNoob69 said:
> @RuyLopez1000 said:
> > If a candidate move is 1-2 pawns (100cp = 1p) from the optimal move eval, then wouldn't a massive amount of moves, be considered a candidate at depth 1? I mean it feels like at depth 1 surely a lot of moves would be classified within 1-2 pawns from the optimal move considering how large a margin that is? And if a large amount of moves has the same price, then that wouldn't give any info.
>
> It was a general concept. For example I am just now coding something that considers the first time a move entered the engine PVs the depth at which it "figured it out". This changes significantly, though, if I configure 1pv, 10 pvs or 500. In other places in LiChess Tools I calculate the winning probability based on centipawns. Anything which is 1% closer to the best estimation is considered good, 10% less is a mistake and 20% is a blunder. The definition of the "candidate move" matters.
>
> I don't know what's the best formula. That's why I was waiting for the likes of @hollowleaf and @jk_182 and @noobmasterplayer123 and @matstc to weigh in :)
>
> I am just saying that even if computers find the moves differently than people, the time (nodes, depth, etc.) they spend to consider a move as possibly good can be considered a cost or price of the move. The higher the cost... err... I don't know. That's what I am trying to figure out.
I will conduct a more in-depth analysis and explore how to express it mathematically. I like the idea, though maybe it can be tweaked more, lets see.
I just wish SF would be more consistent. In the same position, the same move appears at different depths if you try multiple times. Sometimes it's there at depth 6, sometimes at depth 16 and so on. So it's a pretty "in the moment" metric.
I just wish SF would be more consistent. In the same position, the same move appears at different depths if you try multiple times. Sometimes it's there at depth 6, sometimes at depth 16 and so on. So it's a pretty "in the moment" metric.
@TotalNoob69 said:
I just wish SF would be more consistent. In the same position, the same move appears at different depths if you try multiple times. Sometimes it's there at depth 6, sometimes at depth 16 and so on. So it's a pretty "in the moment" metric.
I think that using a single thread should make SF consistent and produce the same results every time
@TotalNoob69 said:
> I just wish SF would be more consistent. In the same position, the same move appears at different depths if you try multiple times. Sometimes it's there at depth 6, sometimes at depth 16 and so on. So it's a pretty "in the moment" metric.
I think that using a single thread should make SF consistent and produce the same results every time
As for "what do you guys think?", well...
Unsupported by literature. There is not a single chess book written out of billions which agrees with this method, so I am skeptical of it.
As for "what do you guys think?", well...
Unsupported by literature. There is not a single chess book written out of billions which agrees with this method, so I am skeptical of it.
The existence of billions of chess books is not supported by literature!! :D
The existence of billions of chess books is not supported by literature!! :D



