@RookyBeach said in #17:
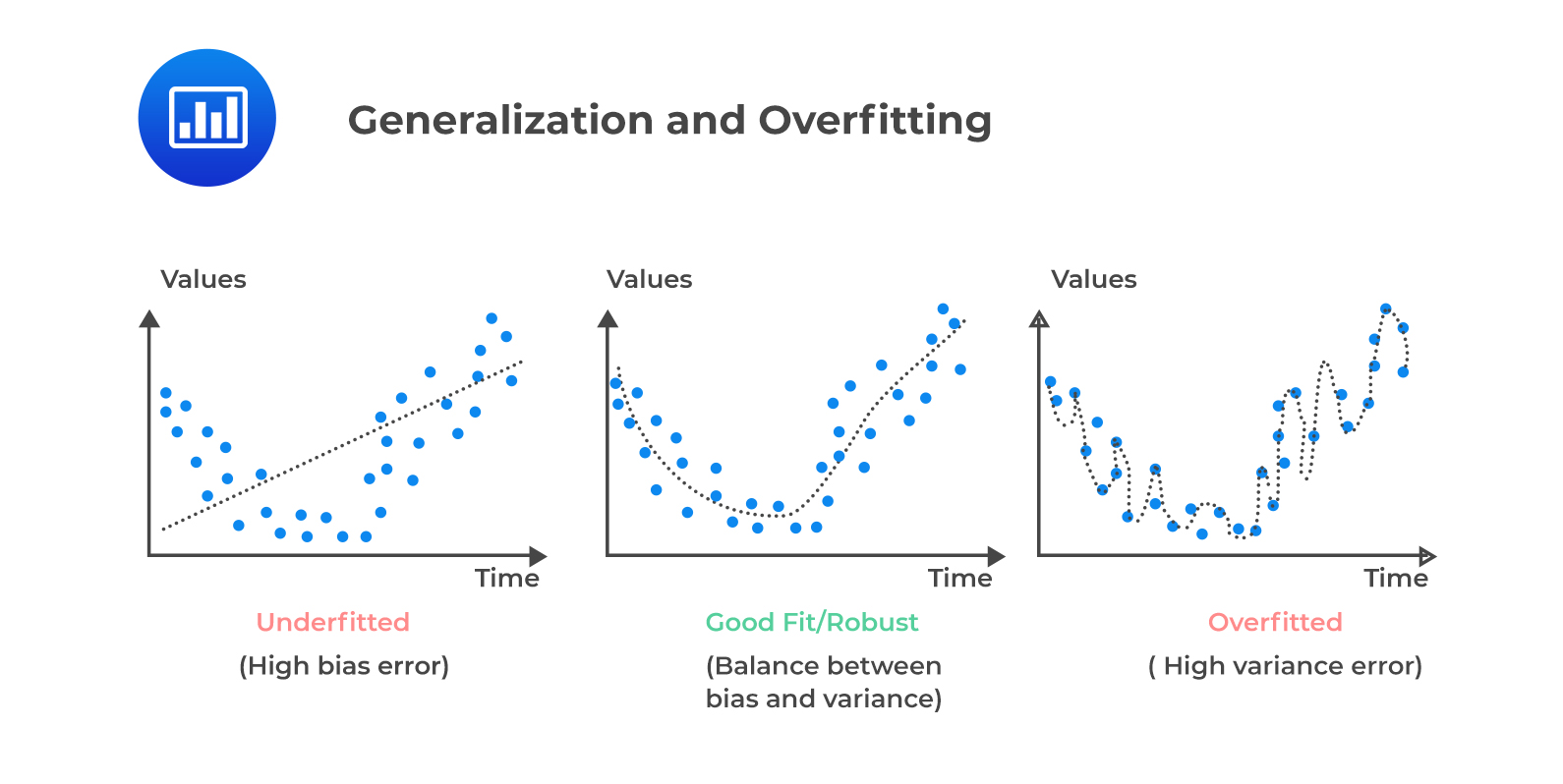
The same happens here, but to a smaller degree when we use piecewise fits for a non piecewise relation
Well, the piecewise approximation is not necessarily more flexible (and overfitting risk) than an equivalent number of parameters family of functions.
The training set risk of being overfitted is in the case one is not doing the double optimization process of having some kind of validation on the held out sub-sample. So we agree there. prediction and generalization from the sampling set to the "reality" of unseen new data, and this sort of things.
With many parameter models, as you mention the NN, one can also go at it a bit more automatically, by adding some regularization terms in the objective function. In regression typically one already has some kind of functional distance to minimize, a regularization term would be about also considering some distance between the function and zero function so that it acts like an under-fitting pressure while the other distance in being pressure to the manifested training data.
Back of using piecewise fits. If the training data is also determining during optimization the number of jumps, maybe that might be different from having an out of data assumption of some function family with a fixed number of parameters.
Why did you think piece-wise fitting would be prone to overfitting? if I understood. I made some arguments but they might not be getting the points.
Afterthoughts. optional.
I also wondering about the notion of hyperparameter here. In some way the out of data assumption can themselves be adjusted, and then the generalization optimization would be tethered to that optimization not being at risk of fitting the sampling errors of the data of interest (that we think is informative about the target phenomenon). This is why I make a distinction between "out of data" and wihtin data. It might be more about this kind of modeling flow. But if this cross-over method (my words) is not having any framework that question is just a musing of mine I guess.
@RookyBeach said in #17:
> The same happens here, but to a smaller degree when we use piecewise fits for a non piecewise relation
Well, the piecewise approximation is not necessarily more flexible (and overfitting risk) than an equivalent number of parameters family of functions.
The training set risk of being overfitted is in the case one is not doing the double optimization process of having some kind of validation on the held out sub-sample. So we agree there. prediction and generalization from the sampling set to the "reality" of unseen new data, and this sort of things.
With many parameter models, as you mention the NN, one can also go at it a bit more automatically, by adding some regularization terms in the objective function. In regression typically one already has some kind of functional distance to minimize, a regularization term would be about also considering some distance between the function and zero function so that it acts like an under-fitting pressure while the other distance in being pressure to the manifested training data.
Back of using piecewise fits. If the training data is also determining during optimization the number of jumps, maybe that might be different from having an out of data assumption of some function family with a fixed number of parameters.
Why did you think piece-wise fitting would be prone to overfitting? if I understood. I made some arguments but they might not be getting the points.
Afterthoughts. optional.
I also wondering about the notion of hyperparameter here. In some way the out of data assumption can themselves be adjusted, and then the generalization optimization would be tethered to that optimization not being at risk of fitting the sampling errors of the data of interest (that we think is informative about the target phenomenon). This is why I make a distinction between "out of data" and wihtin data. It might be more about this kind of modeling flow. But if this cross-over method (my words) is not having any framework that question is just a musing of mine I guess.




{kind=link}